

Making Machines Talk: Formulating Research Questions
The Challenge: The Male Default in Assistive Text-To-Speech (TTS)
Gendered Innovation 1: Text-To-Speech Technologies Producing a Variety of Women's and Men’s Voices
Method: Rethinking Research Priorities and Outcomes
Method: Analyzing Sex
Gendered Innovation 2: Understanding Gender in Speech
Method: Analyzing Gender
Factors Intersection with Sex and Gender: Expanding Speech Databases
Conclusions
Next Steps
The Challenge: The Male Default in Assistive Text-To-Speech (TTS)
In Europe and the U.S., text-to-speech systems are in use for two primary purposes:
- 1. Assistive Technologies for Users with Disabilities: TTS can allow people with mutism and other severe speech disorders to communicate verbally by converting typed text to speech. TTS is also used to read aloud the contents of books, newspapers, websites, etc. to blind users (Dutoit, 1997). This latter functionality is especially important for allowing vision-impaired people to access the internet (Pal et al., 2011).
- 2. Human/Computer Interfaces in Consumer Products: For example, global positioning system (GPS) receivers often utilize TTS to “read” directions to a driver (Berstis, 2001).
Early assistive TTS systems, such as the Votrax Type’N’Talk, were “incapable of generating female voice pitches” (Walsh et al., 1986; Klatt et al., 1990). This historic male default in speech synthesis—a bias that was likely unconscious and may have arisen as a result of most professionals in related fields being men—can restrict self-expression. For example, speech synthesis engineer Dennis Klatt described the case of a young U.S. woman injured in an automotive collision who “refused to use a talking aid because it made her sound masculine” (Klatt, 1987). Another young woman with cerebral palsy reported feeling demoralized that the only speech aid available to her produced a male voice (Lupkin, 1998).
Gendered Innovation 1: Text-To-Speech Technologies Producing a Variety of Women's and Men’s Voices
In 1984, the U.S.-based Digital Equipment Corporation (DEC) began marketing DECtalk, a TTS platform (Leong, 1995). DECtalk was developed in large part
by Klatt, who articulated “the possibility of fitting the voice characteristics to
the user, particularly the advantage of giving women a femalelike voice and
children a childlike voice” as “a potential advantage of DECtalk” for assistive
purposes (Klatt, 1987). The DECTalk platform supported five voices—two adult female, two adult male, and one child (Turunen et al., 2004). DECTalk’s voices represented male and female voices in overtly stereotypical ways. All voices
were personified, and introduced themselves to the user by name. “Huge Harry,” one of the male voices stated, “I am a very large person with a deep voice. I can
serve as an authority figure,” while “Whispering Wendy” one of the female voices asked, “I have a very breathy voice quality. Can you understand me even though
I am whispering?” A sample of these voices can be heard in the audio clip at
right (Klatt, 1987).
Both women’s and men’s voices soon became standard features of TTS systems, such as Apple Computer Corporation’s MacInTalk Professional. Importantly, these systems produce female and male voices with similar intelligibilities (Rupprecht et al., 1995)—see Method.
Method: Rethinking Research Priorities and Outcomes
The historic male default in speech synthesis limited the use of the technology. Engineers recognized that expanding the range of voices available would expand the TTS user base, and began comparative studies of women and men’s voices to gain knowledge of potential sex differences in human voices—see Analyzing Sex. Producing realistic-sounding female and male voices is important from both humanitarian and economic points of view.
View General Method
Women and men’s voices differ; strong evidence for this includes the fact that listeners can identify the sex of an adult speaker with high accuracy, even in the absence of other audio or visual cues. Identification does not require that the speaker and listener share a common language, nor does it require entire words to be spoken. For example, human test subjects who are provided with recordings of single vowel sounds correctly identify the sex of the speaker in 98.9% of attempts (Whiteside, 1998)—see Method.
Method: Analyzing Sex
Sex differences account for some (but not all) of the observed differences between women and men’s voices. Anatomical and physiological differences—in the size and shape of vocal folds, vocal tract length, and the length of the pharynx, etc.—give rise to differences in pitch. Women’s voices are on average higher in pitch than men’s due to women’s vocal cords being shorter and lighter, giving the average woman a fundamental frequency “approximately twice the male frequency” (Simpson, 2009).
View General Method
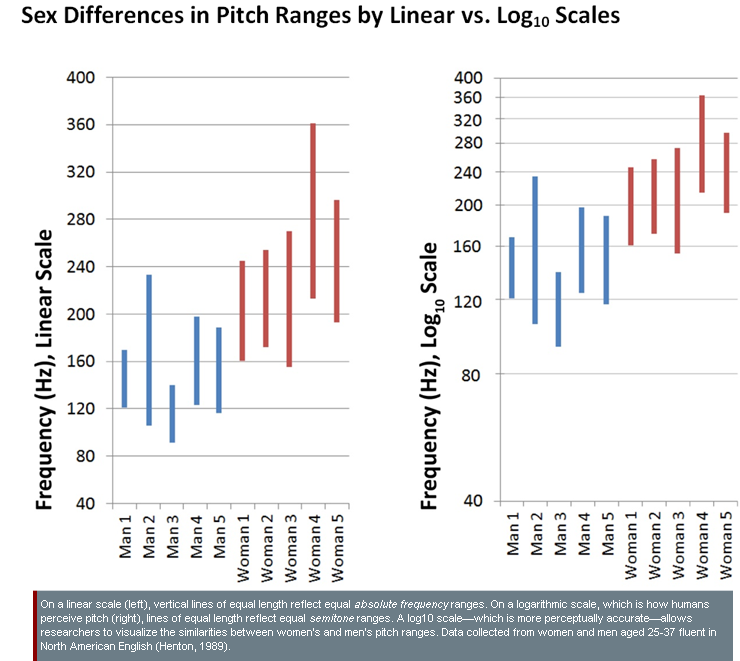
Comparisons of women’s and men’s pitch ranges depend on how pitch is defined. When women’s and men’s voices are compared by absolute frequency range, studies generally show that women have a wider range than men. Historically, some researchers have used this observation to support the stereotype that women’s voices are dramatic, emotional, excitable, irrational, etc. (McConnell-Ginet, 1983). Importantly, comparison by absolute frequency range does not reflect psychoacoustics. Humans perceive pitch range not by “measuring hertz, but by using a logarithmic [or semitone] scale” (Henton, 1989). Comparing women’s and men’s voices by semitones suggests that, while women have a greater absolute frequency range, women and men have similar semitone ranges in normal speech. In this case, rethinking language and visual representations by comparing women’s and men’s pitch ranges on a perceptually-accurate log scale (rather than a linear scale) challenges the stereotype that women’s voices are dramatic and emotional while men’s voices are monotonic and dispassionate—see chart.
Gendered Innovation 2: Understanding Gender in Speech
Gender can influence both the act of speaking and the act of listening (or interpreting what is heard) even when the speaker is a machine. Voices encode rich information about the speaker—such as sex, gender identity, age, and often nationality—even if such information is never directly articulated.
Gender is relevant to speech synthesis because it influences human speech: Creating a TTS system with a “natural” female or male voice involves mimicking both the biological (sex-based) and cultural (gender-based) characteristics of a woman’s or man’s voice.
Method: Analyzing Gender
Research has demonstrated that gender beliefs and behaviors influence the characteristics of real women and men’s voices, as well as real listeners’ responses to synthetic voices.
1. Analyzing gender norms: Long before TTS became widely used, speech researchers recognized that gendered behaviors influence speech (Fant, 1975). Pitch is, to an extent, learned and subject to cultural expectations. Intentional lowering of voice pitch can lend authority to a speaker. This behavior is more gender-appropriate for men than women, but is not exclusively practiced by men—for example, former U.K. Prime Minister Margaret Thatcher was trained by a vocal coach from the National Theatre to lower her voice and make it more authoritative (Atkinson, 1984).
2. Analyzing gender identities: Voices encode expressions of social identity. Studies of transsexuals, some of whom adjust their voice qualities to resemble that of the other sex, have underscored individuals’ abilities to alter their voices to match gender roles (Gorham-Rowan et al., 2006).
3. Analyzing factors intersecting with sex and gender: Gender norms differ cross-culturally. For example, measurements of women and men’s fundamental voice frequencies show different trends among speakers of different languages: Among French speakers, women’s fundamental pitch is about 90 Hz higher than men’s, while among Chinese speakers, women’s pitch is only about 10 Hz higher. Researchers have concluded that “it would be unreasonable to account for such large differences in terms of anatomical differences in the populations being investigated” and that “part of the difference must be attributed to learned behaviours” (Simpson, 2009).
View General Method
 Gender identities and norms, then, are encoded in human speech. Research also demonstrates that listeners apply gender norms to synthetic voices:
Gender identities and norms, then, are encoded in human speech. Research also demonstrates that listeners apply gender norms to synthetic voices:
- 1. Human listeners assign sex and gender to machine voices; that is to say, they interpret machine speakers as women or men. Listeners dislike machine voices which seem ambiguous with respect to sex. Sex assignment even occurs when human listeners are fully aware that sample voices are machine-produced. While “ambiguous” voices can be produced synthetically, listeners still attempt to assign sex and gender to such voices; their assignments may take longer to form and may change, but listeners do not interpret “ambiguous” voices as sex-neutral. Further, human listeners consider “ambiguous” voices “strange, dislikable, dishonest, and unintelligent” (Nass et al., 2005). This makes such voices undesirable for use in assistive technologies as well as in broader commercial applications.
- 2. Listeners apply gender stereotypes to synthetic voices which sound “female” or “male.” This, in turn, influences what stereotypes listeners will use when judging the competence, persuasiveness, attractiveness, honesty, etc. of a voice. A study of U.S. elementary school students aged 9 to 11 years showed that female synthetic voices were judged more likeable and credible than male synthetic voices in discussing stereotypically-feminine topics (such as skin care and cosmetics). When the topic was stereotypically-masculine (such as football), male synthetic voices were judged more likeable and credible (Lee et al., 2007; Niculescu et al., 2009). These results reflect the stereotypes held by research subjects interacting with synthetic speech.
That human listeners apply gender stereotypes to synthetic speech raises fundamental questions about how speech synthesis is used. In particular, the goal of adapting synthetic speech to users’ preferences can be fundamentally at odds with the goal of challenging stereotypes. For example, the automobile manufacturer Bayerische Motoren Werke (BMW) initially marketed vehicles with an onboard computer which “spoke” with a female voice through TTS. However, some users objected to “taking directions” from a female voice, and the BMW contractors who redesigned the TTS system “decided that the voice had to suggest a male who was very slightly dominant, somewhat friendly, and highly competent” (Nass et al., 2005). In this case, satisfying users involved using TTS in a way that conformed to—and perhaps promoted—stereotypes. Today, consumers are often offered the choice of a female or male voice, language, and national accent.
Factors Intersecting with Sex and Gender: Expanding Speech Databases
One approach to TTS is concatenative synthesis, which operates by linking together segments of pre-recorded natural human speech.The European Union’s Human-Machine Interaction Network on Emotion (HUMAINE) project, first established under the Framework Programme 6 (FP6), has supported cutting-edge research that expanded speech databases for EU languages (Roddie, 2010). Researchers assembling databases from recordings of Spanish and German speakers have sampled equal numbers of women and men (Barra-Chicote et al., 2008; Burkhardt et al., 2005). Researchers have also worked to create synthetic voices capable of speaking words in different languages and regional dialects—for example, researchers in Spain have worked to produce “two high-quality voices […] one male and one female […]” which support “the Central Catalan dialect, but also Spanish, Galician, Euskera, and English” pronunciations (Bonafonte et al., 2009). Similar work elsewhere has focused on different accents and dialects of English (such as British, U.S. American, Australian, Welsh, and South Asian), German (used, for example, in different parts of Germany and Austrian), and French (such as Swiss and Parisian) (Miller et al., 2011; Pucher et al., 2010; Yan et al., 2003; Sen et al., 2002).
Synthetic speech capable of imitating different regional and socio-economic dialects has the same potential for promoting stereotypes as speech which is identifiably female or male. There is reason to suspect that listeners will interpret dialect-marked synthetic speech according to stereotypes about race, ethnicity, socioeconomic status, geographic location, etc. (Pucher et al., 2009).
Conclusions
Producing female synthetic voices was an important step in speech synthesis, and helped to broaden the user base for assistive TTS. However, the ability to produce “male” and “female” voices carries the potential to reinforce gender stereotypes. Computerized TTS systems are effectively social actors, and the social messages they send depend upon the underlying technology (for example, the technical characteristics of female and male voices), how it is used (for example, what synthetic voice a company uses to represent a product), and how users respond (Lee, 2008).
Next Steps
Researchers are working to create speech synthesizers with greater flexibility to produce voices in different languages and dialects and to represent women and men speakers of different ages, backgrounds, etc. Important developments include:
- 1.Creating Affective Speech: Natural human speech projects information about the speaker’s emotional state, and affect “is desirable in synthesized speech for reasons of naturalness, efficiency, and general utility” (Cahn, 1990). However, existing commercial TTS systems—while capable of producing relatively intelligible speech—have limited ability to communicate affect (Rebordao et al., 2009). Affective TTS technologies are an active area of research, both for assistive purposes (such as allowing mute users to express emotion audibly) and for commercial purposes (Gusikhin et al., 2011; Luneski et al., 2010). More generally, computerized systems capable of producing affective speech (and “reading” emotional cues from human speech) are vital to the development of sociable robots.
- 2. Developing Individualized Voices: In addition to conveying information about traits such as sex, age, dialect, affective state, etc., natural voices are unique and can be used to identify human speakers. Assistive TTS technologies generally offer fixed voices with few options for customization. Researchers are developing TTS systems which utilize “residual phonatory abilities” of some mute persons in order to create intelligible speech that reflects aspects of the user’s identity, including the user’s sex and gender (Jreige et al., 2009).
Works Cited
Atkinson, M. (1984). Our Masters' Voices: The Language and Body-Language of Politics. London: Methuen.
Barra-Chicote, R., Montero, J., Marcias-Guarasa, J., Lufti, S., Lucas, J., Fernandez-Martinez, F., Dharo, L., San-Segundo, R., Ferreiros, J., Cordoba, R., & Pardo, M. (2008). Spanish Expressive Voices: Corpus for Emotion Research in Spanish. Madrid: Universidad Politecnica de Madrid.
Berstis, V. (2001). Method and Apparatus for Displaying Real-Time Visual Information on an Automobile Pervasive Computing Agent. United States Patent 6,182,010. January 30.
Bonafonte, A., Aguilat, L., Esquerra, I, Oller, S., & Moreno, A. (2009). Recent Work on the FESTCAT Database for Speech Synthesis. Barcelona: Universitat Politècnica de Catalunya (UPC) Press.
Burkhardt, F., Paeschke, A., Rolfes, M., Sendlmeier, W., & Weiss, B. (2005). "A Database of German Emotional Speech." Proceedings of Interspeech/Eurospeech, 9th Biennial European Conference on Speech Communication and Technology, September 4—8, Lisbon.
Cahn, J. (1990). Generation of Affect in Synthesized Speech. Journal of the American Voice Input/Output (I/O) Society, 8, 1-19.
Dutoit, T. (1997). An Introduction to Text-to-Speech Synthesis. Netherlands: Kluwer Academic Publishers.
Fant, G. (1975). Non-Uniform Vowel Normalization. Kungliga Tekniska Högskolan (KTH) Department for Speech, Music, and Hearing Quarterly Progress and Status Report, 16 (2-3), 1-19.
Gorham-Rowan, M., & Morris, R. (2006). Aerodynamic Analysis of Male-to-Female Transgender Voice. Journal of Voice, 20 (2), 251-262.
Hasselbring, T., & Bausch, M. (2005). Assistive Technologies for Reading. Educational Leadership, 63 (4), 72-75.
Henton, C. (1989). Fact and Fiction in the Description of Female and Male Pitch. Language and Communication, 9 (4), 299-311.
Honorof, D., & Whalen, D. (2010). Identification of Speaker Sex from One Vowel across a Range of Fundamental Frequencies. Journal of the Acoustical Society of America, 128 (5), 3095-3104.
Jreige, C., Rupal, P., & Bunnell, T. (2009). "VocaliD: Personalizing Text-to-Speech Synthesis for Individuals with Severe Speech Impairment." Assets '09: The 11th international Association for Computing Machinery (ACM) Special Interest Group on Accessible Computing (SIGACCESS) Conference on Computers and Accessibility, October 25-27, Orlando.
Klatt, D., & Klatt, L. (1990). Analysis, Synthesis, and Perception of Voice Quality Variations among Female and Male Talkers. Journal of the Acoustical Society of America, 87 (2), 820-857.
Klatt, D. (1987). Review of Text-to-Speech Conversion for English. Journal of the Acoustical Society of America, 82 (3), 737-791.
Lee, E. (2008). Flattery May Get Computers Somewhere, Sometimes: The Moderating Roles of Output Modality, Computer Gender, and User Gender. International Journal of Human-Computer Studies, 66 (11), 789-800.
Lee, K., Liao, K., & Ryu, S. (2007). Children’s Responses to Computer-Synthesized Speech in Educational Media: Gender Consistency and Gender Similarity Effects. Human Communication Research, 33 (3), 310-329.
Leong, C. (1995). Effects of On-Line Reading and Simultaneous DECtalk Auding in Helping Below-Average and Poor Readers Comprehend and Summarize Text. Learning Disability Quarterly, 18 (2), 101-116.
Luneski, A., Konstantinidis, E., & Bamidis, P. (2010). Affective Medicine: A Review of Affective Computing Efforts in Medical Informatics. Information in Medicine, 49 (3), 207-218.
Lupkin, K. (1998). A Woman's Voice: Interview with Caroline Henton. Speech Technology.
McConnell-Ginet, S. (1983). Intonation in a Man’s World. In Thorne, B., Kramarae, C., & Henley, N. (Eds.), Language, Gender, and Society, pp. 69-88. Rowley: Newbury House.
Miller, J., Mondini, M., Grosjean, F., & Dommergues, J. (2011). Dialect Effects in Speech Perception: The Role of Vowel Duration in Parisian French and Swiss French. Language and Speech, Online in Advance of Print.
Nass, C., & Brave, S. (2005). Wired for Speech: How Voice Activates and Advances the Human-Computer Relationship. Cambridge: MIT Press.
Niculescu, A., van der Sluis, F., & Nijhot, A. (2009). "Femininity, Masculinity, and Androgyny: How Humans Perceive the Gender of Anthropomorphic Agents." Proceedings of the Thirteenth International Conference on Human-Computer Interaction, July 19th—July 24th, San Diego.
Pal, J., Pradhan, M., Shah, M., & Babu, R. (2011). "Assistive Technology for Vision Impairments: An Agenda for the Information Communications Technology and Development (ICTD) Community." 21st Annual Meeting of the International World Wide Web Conference Committee (IW3C2), March 28—April 1, Hyderabad, India.
Pucher, M. Schabus, D., Yamagishi, J., Neubarth, F., & Strom, V. (2010). Modeling and Interpolation of Austrian German and Viennese Dialect in Hidden Markov Model (HMM)-Based Speech Synthesis. Speech Communication, 52 (2), 164-179.
Pucher, M., Schuchmann, G., & Fröhlich, P. (2009). Regionalized Text-to-Speech Systems: Persona Design and Application Scenarios. Multimodal Signals: Cognitive and Algorithmic Issues, 5398, 216-222.
Rebordao, A., Shgaikh, M., Hirose, K., & Minematsu, N. (2009). "How to Improve Text-to-Speech (TTS) Systems for Emotional Expressivity." 10th Annual Conference of the International Speech Communication Association, September 6-10, Brighton.
Roddie, C. (2010). HUMAINE: Human-Machine Interaction Network on Emotion. Luxembourg: European Commission Publications Office.
Rupprecht, S., Beukelman, D., & Vrtiska, H. (1995). Comparative Intelligibility of Five Synthesized Voices. Augmentative and Alternative Communication, 11 (4), 244-248.
Sen, A., & Samudravijaya, K. (2002). Indian Accent Text-to-Speech System for Web Browsing. Sadhana, 27 (1), 113-26.
Simpson, A. (2009). Phonetic Differences between Male and Female Speech. Language and Linguistics Compass, 3 (2), 621-640.
Turunen, M., & Salonen, E. (2004). "Speech Interface Design." Tampere Unit for Computer-Human Interaction Speech Interface Design Workshop, September 13, Tampere, Finland.
Whiteside, S. (1998). Identification of a Speaker’s Sex: A Study of Vowels. Perceptual and Motor Skills, 86 (2), 579-584.
Yan, Q., & Vageshi, S. (2003). Analysis, Modeling and Synthesis of Formants of British, American and Australian Accents. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, 1, 712-715.
Speech synthesis—in which machines generate human-like speech—has applications in basic linguistic research, assistive technologies for people with disabilities, and commercial devices and software.
The historic male default in speech synthesis can limit the use of this technology. A young woman injured in a car accident, for example, refused to use a talking aid when only male voices were available.
Gendered Innovation:
Today, we recognize that analyzing sex (biological factors) and gender (socio-cultural factors) is important for creating text-to-speech systems with a range of voices for assistive technologies and other human/computer interfaces. Gender assumptions in particular influence both the act of speaking and the act of listening (or interpreting what is heard) even when the speaker is a machine.
Gender identity and norms, for example, are coded into speech. For example, among French speakers, women's fundamental pitch is about 90 Hz higher than men's, while among Chinese speakers, women's pitch is only about 10 Hz higher. Researchers have concluded that "it would be unreasonable to account for such large differences in terms of anatomical differences in the populations being investigated" and that "part of the difference must be attributed to learned behaviors" or gender norms.
Listeners apply gender norms to synthetic voices, and don't like machine voices that are "ambiguous" with respect to sex/gender. This makes such voices undesirable for use in assistive technologies as well as in broader commercial applications. Moreover, when listeners "hear" a male or female voice, they tend to overlay gendered stereotypes onto the voice. Companies may lose market share when choosing voices for customers. BMW, for example, was forced to recall its cars with a female voice in its initial navigation systems. Apple was unsuccessful with Siri, its first female iPhone assistant.
The solution is to offer consumers choices. Researchers are working to create machines with greater flexibility to produce voices in different languages and dialects and to represent women and men speakers of different ages, gender identities, accents, geographic locations, etc.





